What would we do if we tried training multiple models but the results were not good enough? Let think about ensemble learning. Ensemble learning is a machine learning technique that combines the predictions of multiple weak learners to create a strong learner.
Ensemble learning offers several advantages:
Improved Accuracy: Combining predictions from diverse models often leads to better overall performance compared to individual models.
Reduced Overfitting: Ensemble methods trade higher bias for lower variance, in order to mitigate overfitting, especially when using techniques like bagging and proper hyperparameter tuning.
Increased Robustness: Ensemble models are more resilient to noisy data and outliers.
Enhanced Generalization: The diversity of models in an ensemble allows for better generalization to unseen data.
However, ensemble learning also comes with increased computational complexity and may require more careful tuning of hyperparameters. The choice of ensemble method depends on the characteristics of the data and the specific problem at hand.
Key ensemble learning techniques
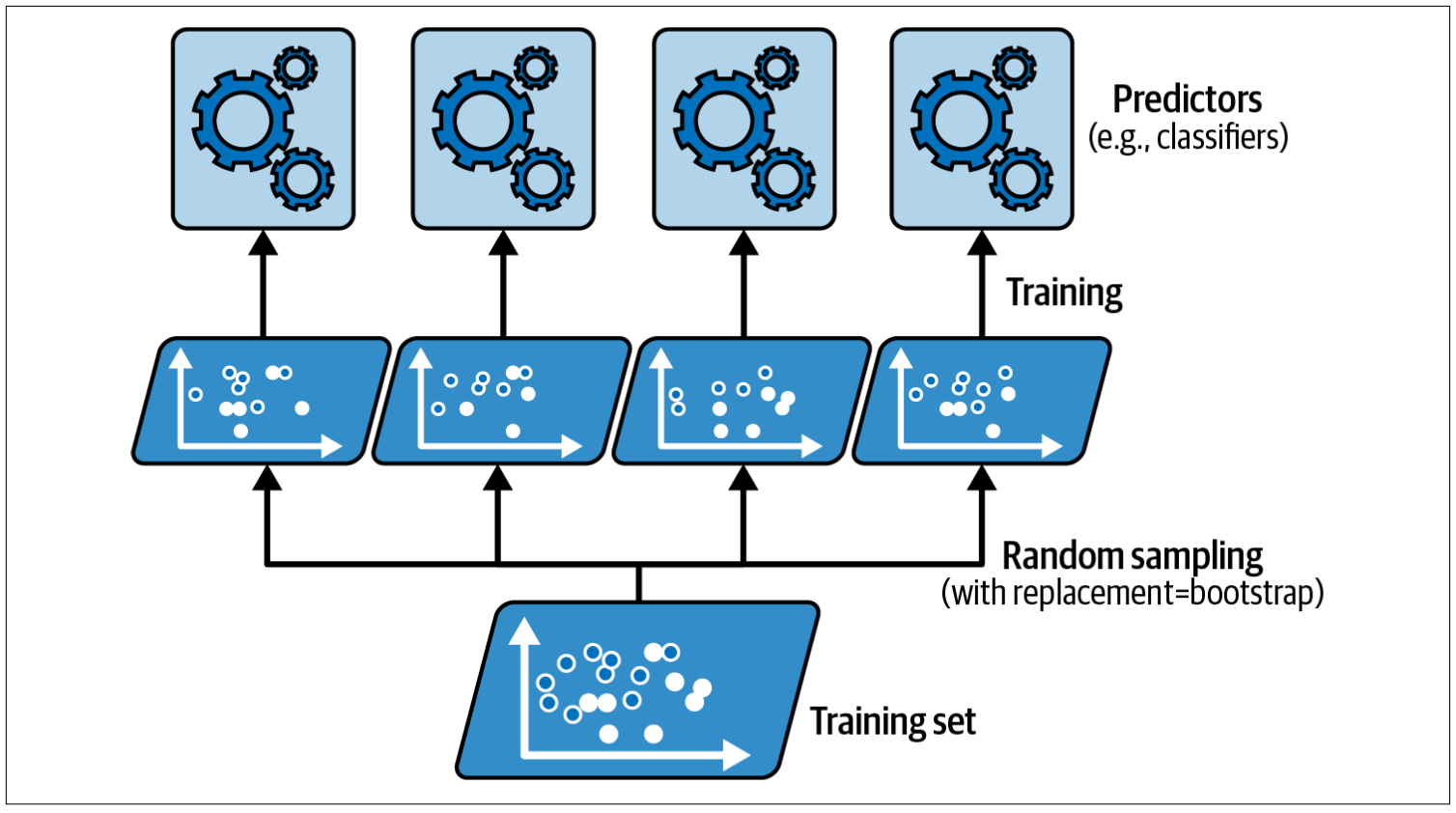
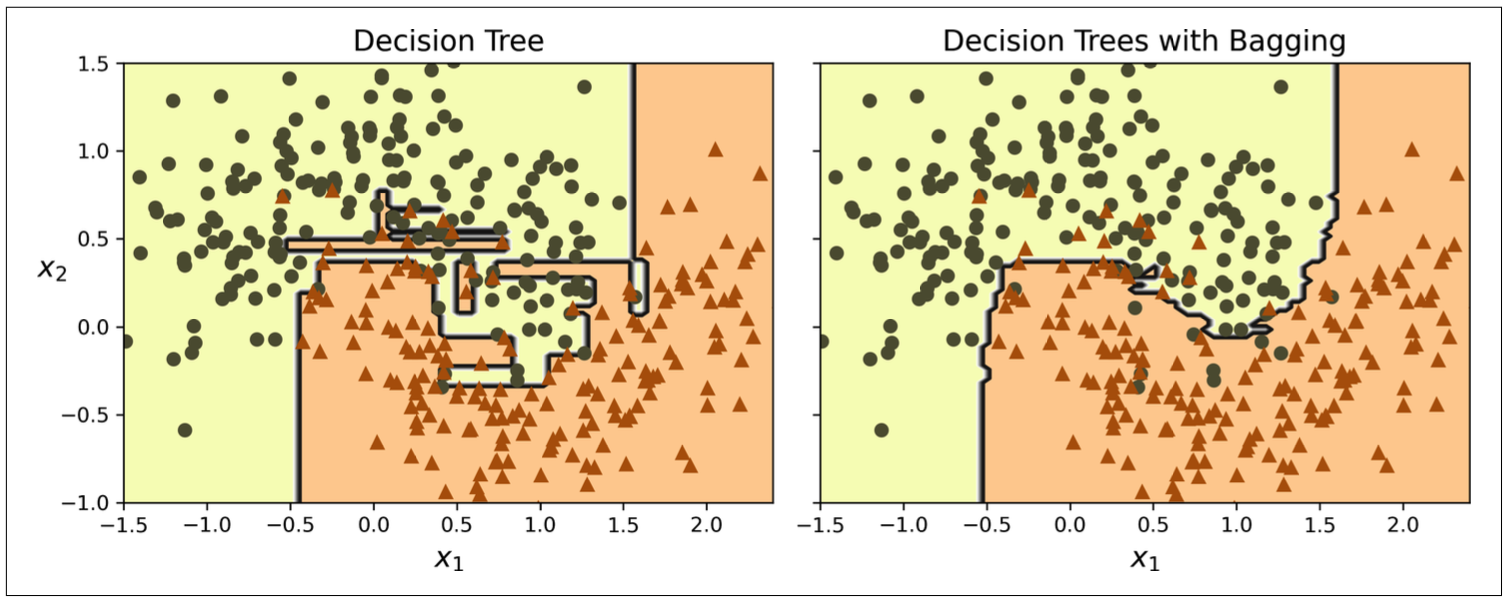
Bagging (Bootstrap Aggregating): Training multiple learner parallely on subset of dataset sampled with/without replacement (equally variables) using random subset of variables at each step of spliting internal node. Measure performance by ‘Out-Of-Bag Error’. Random Forests (ensemble of decision trees) are a notable example.
Boosting: Training multiple learner sequentially on full dataset, each subsequent model adjust the weights by correcting the errors of the previous ones (weighted variables). Popular algorithms using boosting include AdaBoost, Gradient Boosting (e.g., XGBoost, LightGBM), and CatBoost.
Stacking: Stacking combines predictions from multiple models by training a meta-model on their outputs. Base models act as input features for the meta-model, which learns to make a final prediction.
Random forests, AdaBoost, and GBRT are among the first models you should test for most machine learning tasks, and they particularly shine with heterogeneous tabular data. Moreover, as they require very little preprocessing, they’re great for getting a prototype up and running quickly. Lastly, ensemble methods like voting classifiers and stacking classifiers can help push your system’s performance to its limits.
The simpliest bagging algorithm with no boostrapping and only aggregating. It aggregates predictions by choosing most voted class (hard voting) or class with highest probability (soft voting).
In sklearn.ensemble.VotingClassifier, it performs hard voting by default.
from sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import VotingClassifier, RandomForestClassifierfrom sklearn.svm import SVCX, y = make_moons(n_samples=500, noise=0.30, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)voting_clf = VotingClassifier( estimators=[ ('lr', LogisticRegression(random_state=42)), ('rf', RandomForestClassifier(random_state=42)), ('svc', SVC(random_state=42))] )voting_clf.fit(X_train, y_train)print('Accuracy of individual predictor:')for name,clf in voting_clf.named_estimators_.items():print(f'{name} = {clf.score(X_test,y_test)}')print(f'Accuracy of ensemble: {voting_clf.score(X_test, y_test)}')
Accuracy of individual predictor:
lr = 0.864
rf = 0.896
svc = 0.896
Accuracy of ensemble: 0.912
Random forest is ensemble of decision trees using bagging on full dataset. RandomForestClassifier has all the hyperparameters of DecisionTreeClassifier and BaggingClassifier to control ensemble.
Although we have state that bagging method treat all features equally, there is still a method to get the weighted average after training by look at the proportion of training samples used to reduce impurity. This can be used to perform features selection.
We will talk about AdaBoost (adaptive boosting) and Gradient boosting.
11.2.1 AdaBoost
The algorithm work by training predictors sequentially. First it trains the base model and make predictions, then train the new pridictor weighting more on misclassified instances of the previous one, and so on. This is one of the most powerful model, and its main drawback is just do not scale really well.
Figure 11.3: AdaBoost
Fundamentals:
Initialize weights w(i) of each instance equal to 1/m
Train base predictor
Predict and get weighted error rate r(j) Weighted error rate of the j(th) predictor \[r_j = \sum_{i=1}^{m}w^{(i)}\;\;\;with\;yhat_{j}^{(i)}\;≠\;y^{(i)}\]
Compute predictor’s weight α(j). The more accurate the predictor, the higher its α(j)
\[α_j = ηlog(\frac{1-r_j}{r_j})\]
Update instances’s weights. This give more weights on misclassified instances.
As same as AdaBoost, but instead of tweaking the instance weights, this method tries to fit the new predictor to the log loss (classification)/residual errors (regression) made by the previous predictor.
Regularization technique: shrinkage, adjust the learning rate.
Sampling instances: Stochastic Gradient Boosting; set subsample hyperparameter.
Optimize for large dataset. It works by binning the input features, replacing them with integers, in which max_bins ≤ 255. It’s more faster but causes a precision loss => Risk of underfitting.
Learn more about XGBoost, CatBoost and LightGBM
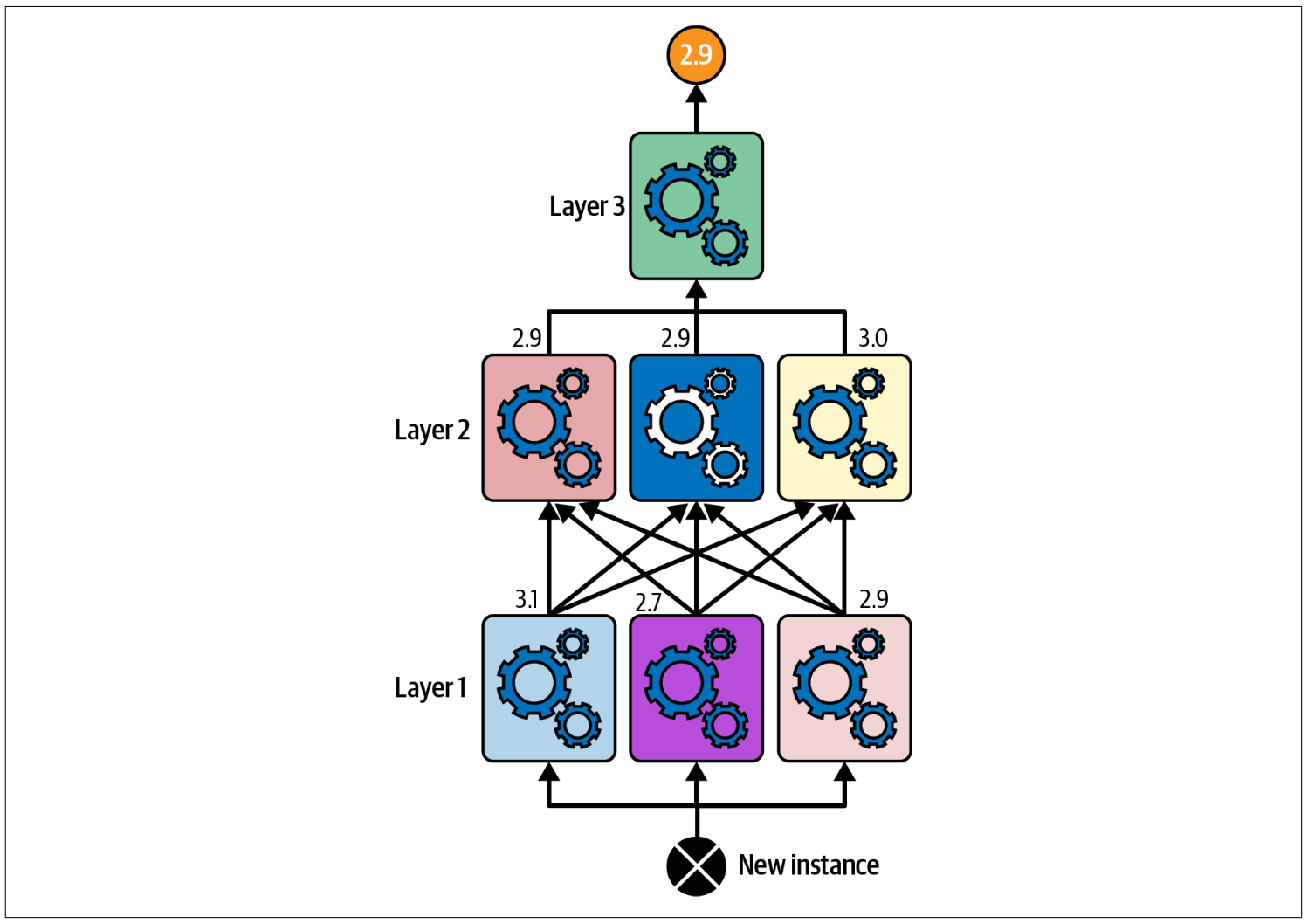
11.3 Stacking (Stacked Generalization)
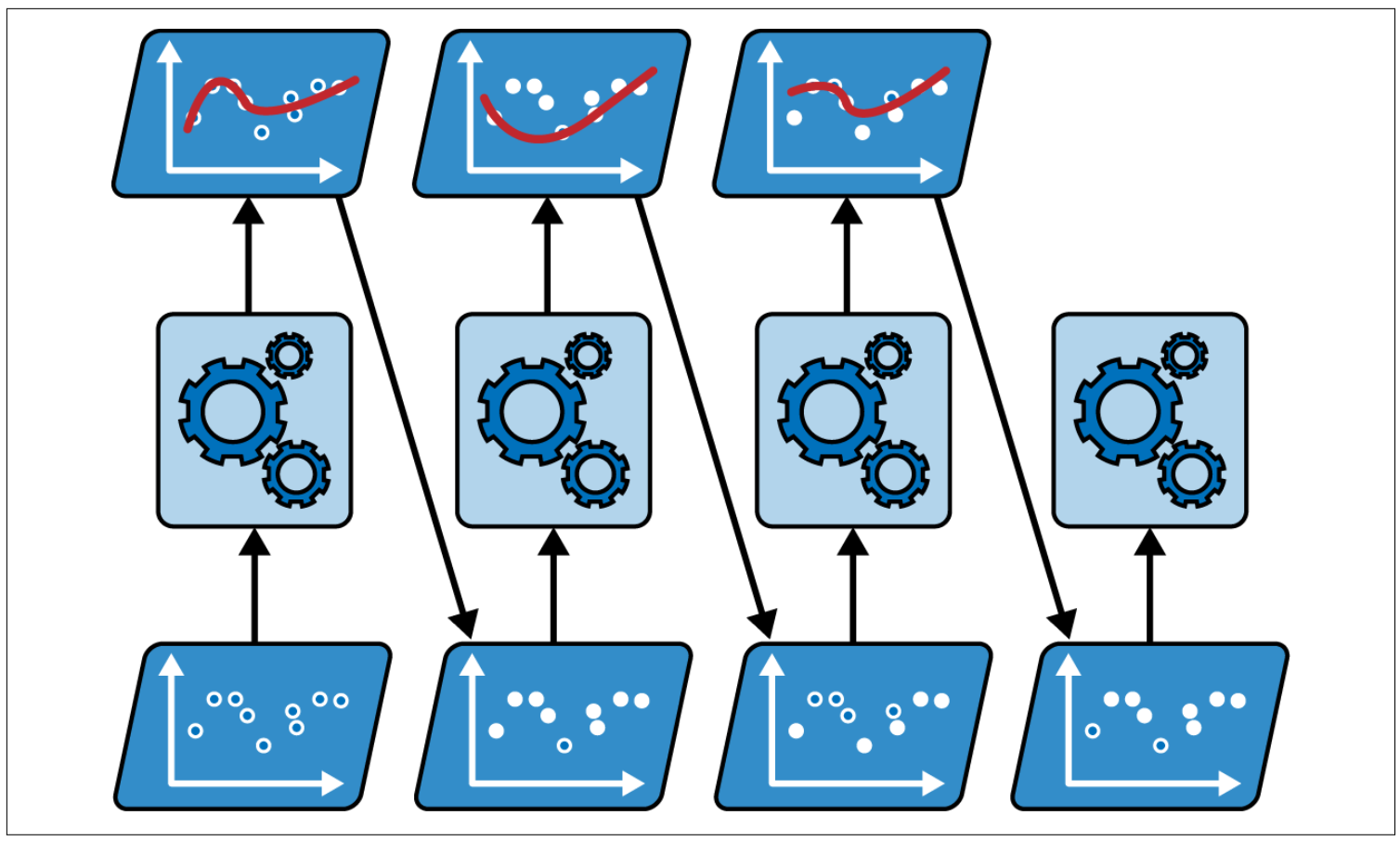
Stacking method works by training a model to aggregate the predictions instead of majority voting like bagging method. This model, also called blender or meta learner, uses the prediction of weak learners (out-of-sample) as input and makes final prediction.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
/usr/local/anaconda3/envs/dhuy/lib/python3.11/site-packages/sklearn/svm/_classes.py:32: FutureWarning:
The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
0.896
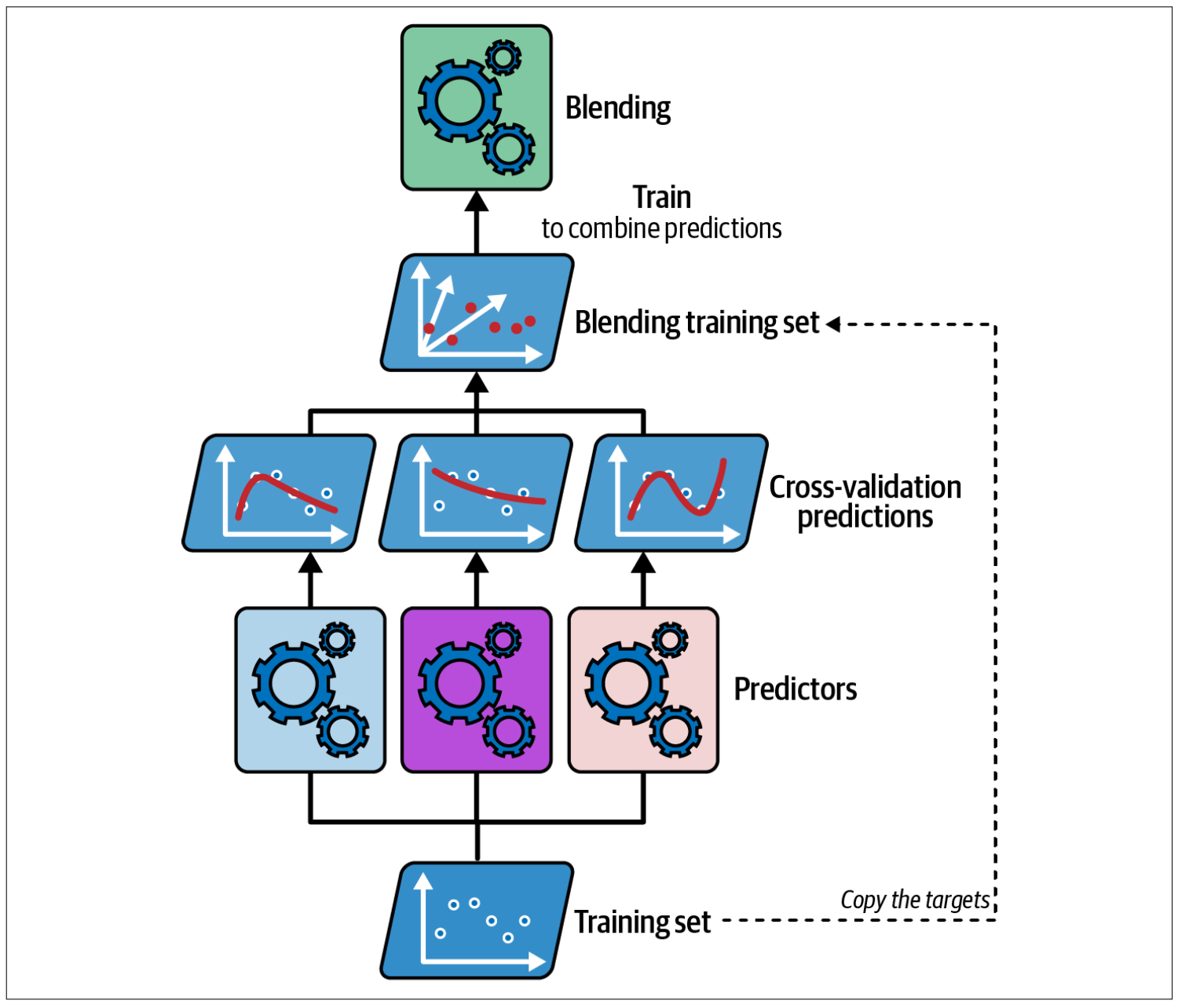
It can be created with layer of blenders such like this
Figure 11.5: Multilayer stacking
If you don’t provide a final estimator, StackingClassifier will use LogisticRegression and StackingRegressor will use RidgeCV.